데이터 파악하기
현재 다운 받은 데이터는 train.csv, test.csv, sample_submission.csv으로 총 3가지이며, 모두 csv파일이다.
데이터 넣기
로컬에 저장되어 있는 데이터를 코랩에 업로드하였다.

업로드 한 후 데이터를 불러오고 살펴보기 위해 pandas 라이브러리를 사용하였다.
데이터 확인
이 후 데이터 불러와 보고, 확인하였다.
이렇게 데이터가 잘 나오는 것을 확인할 수 있다.
그리고 head( ), tail( ) 메소드를 이용하여 최상단 데이터 5개와 최하단 데이터 5개를 표시하여 칼럼들을 살펴봤다.
칼럼은 총 13개이고, store는 1~45, date는 2010 5월 ~ 2012 9월까지 있는 것이 파악이 된다.
마지막으로 데이터 결측치 및 변수들의 탑입을 확인하기 위해 info( ) 메소드를 활용하여 결측치를 찾아냈다.
데이터를 확인해보니 프로모션 1 ~ 5까지 결측치가 존재한다는 것을 알 수 있다.
데이터 시각화
시각화를 위해 나는 matplotlib을 활용할 예정이다.
bins = 50 입력하여 데이터의 분포를 더 정교하게 만들고, 색을 green으로 변경하였습니다.
표를 보면 값들이 대부분 작은 쪽에 몰려 있다.
데이터 전처리
- 결측치(NA) 처리
아까 위에서 프로모션에서 NaN 데이터 존재하는 것을 확인하였다.
이 부분을 채워넣지 않으면 분석을 진행할 수 없다.
왜냐하면 NaN 데이터는 null의 개념으로 이 값을 참조하게 되면 프로그램이 죽어버리게 되기 때문이다.
그래서 NaN 데이터를 채우거나 제거해주어야 하는데 나는 채우는 것이 더 효율적이라 생각해 채워넣었다.
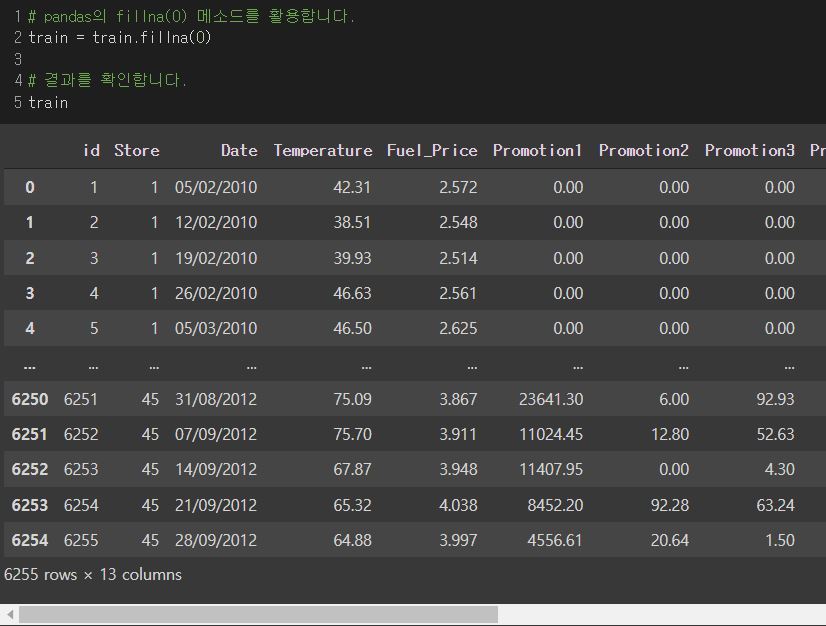
이 후 NaN 데이터들이 0.00으로 채워진 것을 볼 수 있다.
- Date 전처리
Date 칼럼에서 날짜 정보를 확인할 수 있는데 이 날짜 정보가 문자의 형태 (info()로 확인함)로 구성되어 있기 때문에
분석을 위해 숫자로 변환해주어야한다.
그런데 나는 "일 / 월 / 년도" 중 월 정보만 사용할 것이다. 왜냐하면 현재 데이터가 주간 데이터이기 때문이다.
따라서 년도와 일에 대한 데이터는 정보를 오염시킬 우려가 있어 제외하였다.
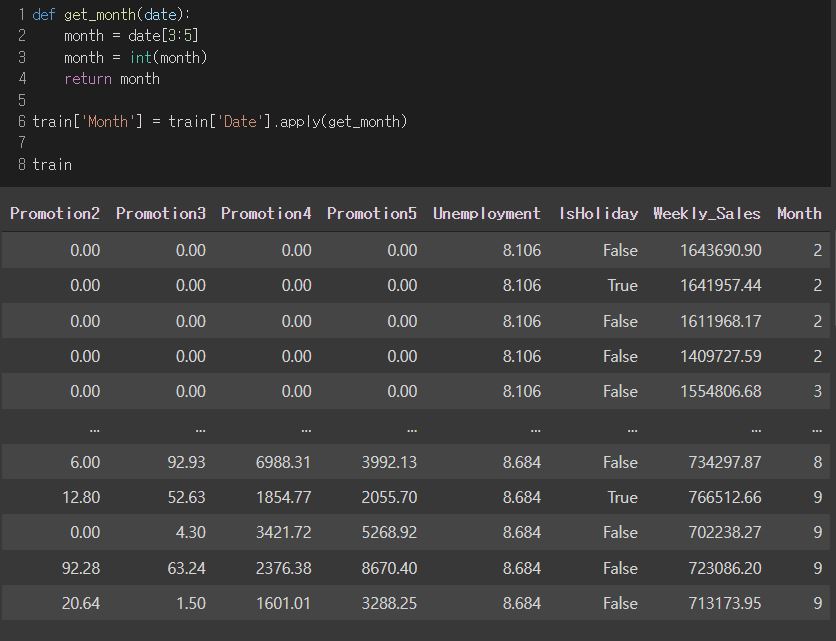
다음 데이터를 4번째와 5번째 글자를 출력하기 위해 슬라이싱하고 int로 변화해주었다.
그리고 Month 칼럼을 만들어 넣었다.
- IsHoliday 전처리
Date 칼럼은 휴일 정보를 포함하고 있다. 그래서 값이 휴일인 경우는 True,
휴일이 아닌 경우는 False 값을 갖도록 코드를 구성하였다.
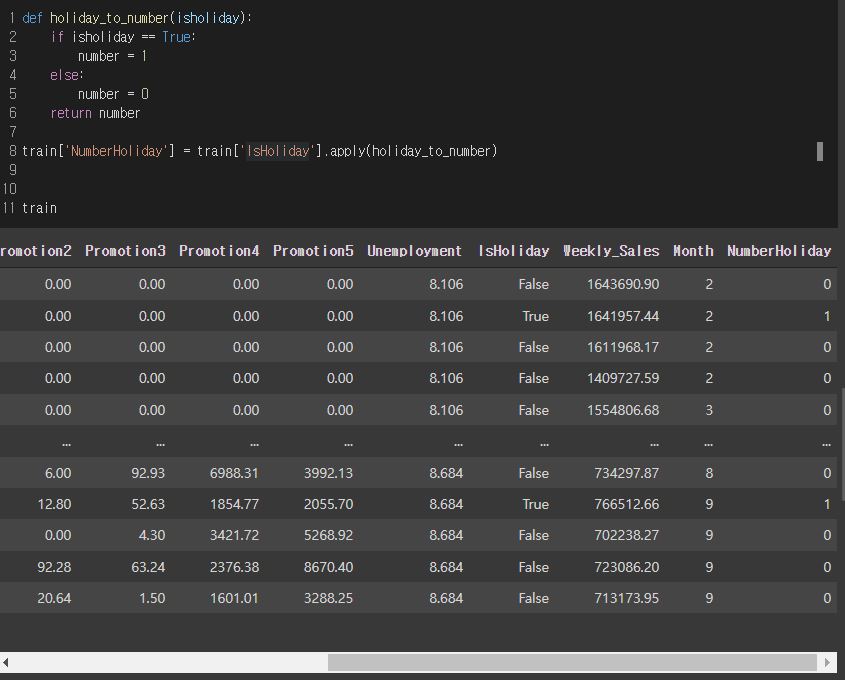
apply메소드는 데이터프레임["컬럼"].apply(함수명)으로 쓰인다.
apply를 쓰면 데이터프레임이나 특정한 컬럼의 값을 일괄적으로 변경할 수 있다.
이렇게 전처리가 완료되었다.
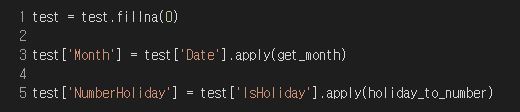
이것을 동일하게 test set에도 적용시켜주면 된다.
Modeling
이제 이 데이터를 사용하여 모델을 학습시켜 예측 결과를 만들어 볼 것이다.
- 선형회귀
수치 예측 문제에 자주 쓰이는 선형회귀 모델을 사용하였다.
독립변수와 종속변수의 관계를 선형식으로 나타내기 때문에 예측이나 추론문제에 많이 쓰인다.
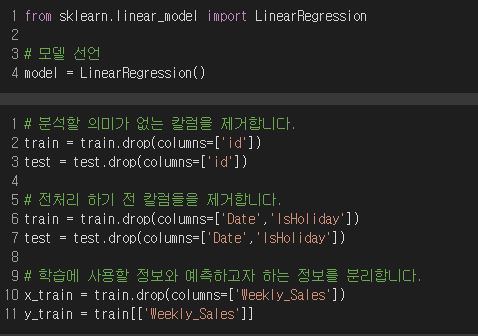
선형회귀를 쓰기 위해 sklearn 라이브러리를 사용하였고, 최종적으로 필요없는 칼럼들을 제거하고, 분리합니다.
이 후 모델 fit 메소드를 이용하여 모델학습을 시킨다.
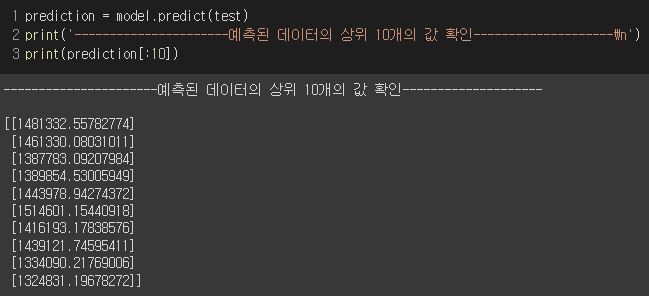
마지막으로 sklearn을 이용해 모델에 predict() 메소드를 적용시켜 상위 10개의 값을 확인할 수 있다.
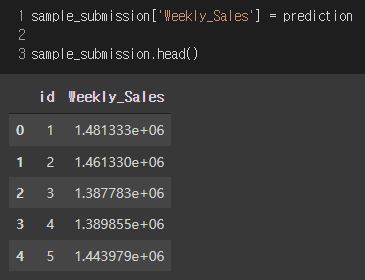
제출
예측된 값을 정답파일과 병합하고, 정답파일의 데이터프레임을 마지막으로 확인한다.
마지막으로 csv안에 아무 옵션도 지정해주지 않으면 인덱스도 데이터에 포함되어 저장되기 때문에
index를 False로 하여 포함시키지 않고 저장한다.

이번 데이터 분석은 내가 중고차 가격 예측 이 후 두번째로 해낸 데이터 분석이다.
처음과 지금의 차이점은 내가 파이썬의 개념에 대해 공부하여 어떤 구조로 돌아가는지 알 수 있다는 것과
모르는 것이 나와도 개념이 잡혀있어 검색을 해도 이전보다 수월하게 새로운 개념을 수용할 수 있다.
앞으로도 계속 지속적으로 데이터 분석을 공부하여 상위 티어로 가고 싶다!
'데이터 분석 > 데이콘' 카테고리의 다른 글
| 데이콘 public 35등 private 45등! (0) | 2022.12.25 |
|---|---|
| 데이콘 Public 42등 Private 29등! (0) | 2022.11.01 |
댓글