728x90
지도학습 vs 비지도학습
- 비지도 학습의 기본 아이디어는 X를 설명할 수 있는 z가 존재한다고 가정하고 학습진행
- 여기서 z는 잠재변수라고 한다.
- z의 해는 여러개가 존재한다.

예를 들면 우리가 100을 값을 구하기 위한 방법은 25 X 4, 1 X 100, 20 X 5와 같이 여러가지 방법이 있다.
이를 잠재변수라고 비유할 수 있다.
차원의 저주
- 차원이 증가할수록 학습데이터의 수에 비해 특성의 차원수가 많아져서 성능이 저하되는 현상
model = LGBMClassifier(random_state=SEED)
cv = KFold(n_splits=5,shuffle=True,random_state=SEED)
scores = cross_val_score(model,x_train,y_train,cv = cv, scoring="roc_auc", n_jobs=-1)
scores.mean()
=> 0.8900131161304283
타이타닉 데이터를 결측치를 채우고, ticket과 cabin을 원핫인코딩을 활용해 차원을 늘려보았다.
PCA(Principal Component Analysis)
- 주성분 분석
- 새로 파생된 주성분이 특성이다!
- 주요 아규먼트
- n_components : 주성분의 수
from sklearn.decomposition import PCA
pca = PCA(n_components=200,random_state=SEED) # 200개로 줄인다.
pca.fit(sparse_features)
=> PCA(n_components=200, random_state=42)
주성분을 200개로 줄였다.
sum(pca.explained_variance_ratio_)
PCA를 통해 주성분에 의해 설명되는 분산 비율을 구하였다.
데이터프레임 만들기
tmp = pd.DataFrame(pca.transform(sparse_features)).add_prefix("pca_")
x_train = pd.concat([features,tmp],axis=1)
x_train.head()
축소 후 교차 검증
model = LGBMClassifier(random_state=SEED)
scores = cross_val_score(model,x_train,y_train,cv = cv, scoring="roc_auc", n_jobs=-1)
scores.mean()
=> 0.9013099786869494
주성분 개수에 따른 분산 비율
components = np.arange(200,901,50)
for c in components:
v = sum(pca.explained_variance_ratio_[:c])
print(f"{c}개 주성분: {v}") # 개수가 적은 주성분이 더 좋은 성능을 발휘할 수도 있다.
=>
200개 주성분: 0.527159387064588
250개 주성분: 0.5818057014232519
300개 주성분: 0.6343174560575218
350개 주성분: 0.6634783108864314
400개 주성분: 0.6908014680657634
450개 주성분: 0.7181246252450953
500개 주성분: 0.7454477824244273
550개 주성분: 0.7727709396037593
600개 주성분: 0.8000940967830913
650개 주성분: 0.8274172539624233
700개 주성분: 0.8547404111417553
750개 주성분: 0.8820635683210872
800개 주성분: 0.9093867255004192
850개 주성분: 0.9367098826797512
900개 주성분: 0.9640330398590832
실제 데이터에 결합
pca = PCA(n_components=800, random_state=SEED)
pca.fit(sparse_features)
tmp = pd.DataFrame(pca.transform(sparse_features)).add_prefix("pca_")
x_train = pd.concat([features,tmp],axis=1)
model = LGBMClassifier(random_state=SEED)
scores = cross_val_score(model, x_train, y_train, cv = cv, scoring="roc_auc", n_jobs=-1)
scores.mean()
=> 0.9103647522510643
함수 적용
def get_score(decomp ,features, sparse_features):
tmp = pd.DataFrame(decomp.transform(sparse_features)).add_prefix("decomp_")
x_train = pd.concat([features,tmp],axis=1)
model = LGBMClassifier(random_state=SEED)
scores = cross_val_score(model,x_train,y_train,cv = cv , scoring="roc_auc",n_jobs=-1)
return scores.mean()
get_score(pca,features,sparse_features)
=> 0.9103647522510643
KernelPCA
- 비선형 결합방식
- kernel을 이용해서 비선형으로 결합
- linear(default 값, pca랑 같다.)
- poly(다항식)
- rbf
- sigmoid
- cosine
적용
from sklearn.decomposition import KernelPCA
kpca = KernelPCA(n_components=100,kernel="cosine",n_jobs=-1,random_state=SEED) # kernel바꿔가면서 넣어보기!
kpca.fit(sparse_features)
get_score(kpca,features,sparse_features)
=> 0.9224232825859108
행렬 분해
- 하나의 행렬을 여러개의 행렬의 곱으로 나타내는 것
SVD (Singular Value Decomposition)
- 특이값 분해
- 이상치 탐지 때 사용 (카드 사용거래, 거래 데이터를 축소한 것과 원본데이터의 차이가 적다면 정상, 차이가 많이나면 사기)
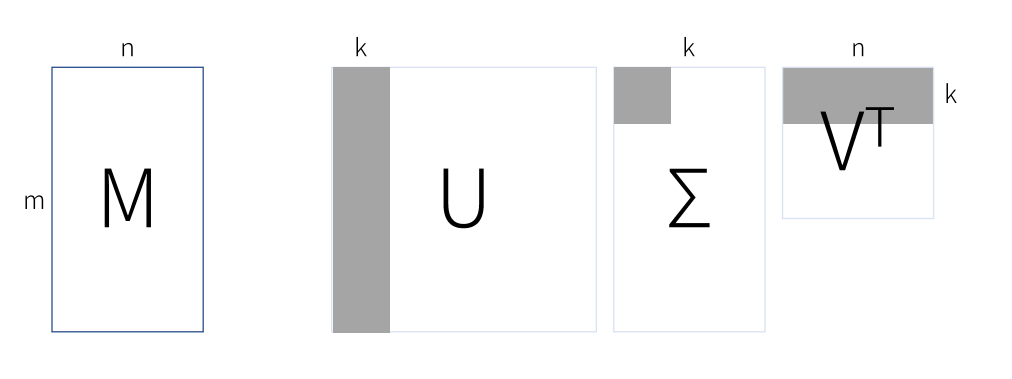
SVD 적용
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=100,random_state=SEED)
svd.fit(sparse_features)
=> TruncatedSVD(n_components=100, random_state=42)
주성분 개수에 따른 분산 비율
sum(svd.explained_variance_ratio_)
=> 0.3929530650654831
스코어
get_score(svd,features,sparse_features)
=> 0.9047766578047938
NMF(Non-negative Matrix Factorization)
- 자연어 때 많이 쓰인다.
- 음수가 안 들어간다.
적용
from sklearn.decomposition import NMF
nmf = NMF(n_components=100,random_state=SEED,max_iter=200)
nmf.fit(sparse_features)
음수 확인해보기
(nmf.components_ < 0).sum()
=> 0
음수가 없다.
get_score(nmf,features,sparse_features)
=> 0.890574647758255
- LDA (Linear Discriminant Analysis) 생략! (책에 있으니 한번 보기!)
- 백화점 데이터에는 좋게 나온다!
Random Projection
- 데이터 포인트 간에 거리를 유지되도록 하면서 특성의 차원을 저차원으로 투영
- GRP(Gaussian Random Project) -> 일반적인 데이터에서 사용!
- SRP(Sparse Random Project) -> 0이 많은 데이터에서 사용!
- 3차원의 피처를 2차원으로 거리를 유지하여 차원을 줄임!
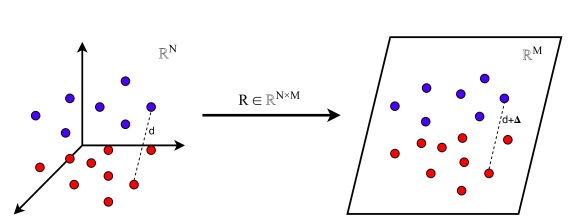
- GaussianRandomProjection
- n_components: 차원수
- "auto": 기본값, eps에 따라 자동으로 차원수를 결정
- eps: 입실론값
- 값이 작을수록 차원이 높아진다.
GaussianRandomProjection 적용
from sklearn.random_projection import GaussianRandomProjection
grp = GaussianRandomProjection(eps=0.4,random_state=SEED)
grp.fit(sparse_features)
get_score(grp,features,sparse_features)
=> 0.9142671033621493
일반적인 데이터에서 많이 사용된다.
- SparseRandomProjection 적용
from sklearn.random_projection import SparseRandomProjection
srp = SparseRandomProjection(eps=0.4,random_state=SEED)
srp.fit(sparse_features)
get_score(srp,features,sparse_features)
=> 0.8953524130060654
0이 많은 데이터에서 사용한다.
비지도 학습의 차원축소를 하여 성능을 높일 수 있다는 것을 이론으로만 배워서 아직 감이 안잡힌다.
실제로 적용해보는 연습을 통해 익혀야할 것 같다,
728x90
'AI 공부 > 머신러닝' 카테고리의 다른 글
| (머신러닝) XAI와 SHAP (1) | 2022.09.15 |
|---|---|
| (머신러닝) data leakage (0) | 2022.09.15 |
| (머신러닝) 모델튜닝 (1) | 2022.09.13 |
| (머신러닝) 앙상블 (0) | 2022.09.13 |
| (머신러닝) 머신러닝 모델 (2) | 2022.09.13 |


댓글