XAI(Explainable Artificial Intelligence)
- 설명 가능한 AI
데이터 가져오기
import pandas as pd
import numpy as np
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from lightgbm import LGBMClassifier
df = pd.read_csv(f"{DATA_PATH}titanic.csv")
# 결측치 미리 채우기
df.age = df.age.fillna(df.age.median()) # age 중앙값
df.fare = df.fare.fillna(df.fare.median()) # fare 중앙값
df.cabin = df.cabin.fillna("UNK") # cabin 임의의 문자열로 채우기
df.embarked = df.embarked.fillna(df.embarked.mode()[0]) # embarked 최빈값
# 학습에 바로 사용가능한 특성
cols = ["pclass","age","sibsp","parch","fare"]
features = df[cols]
# 범주형 one-hot encoding
cols = ["gender","embarked"]
enc = OneHotEncoder()
tmp = pd.DataFrame(
enc.fit_transform(df[cols]).toarray(),
columns = enc.get_feature_names_out()
)
features = pd.concat([features,tmp],axis=1) # 특성
target = df["survived"] # 정답값
features.head()
holdout으로 학습 및 검증데이터 나누기
from sklearn.model_selection import train_test_split
x_train,x_valid,y_train,y_valid = train_test_split(features,target,random_state=SEED)
x_train.shape,x_valid.shape,y_train.shape,y_valid.shape
=> ((981, 10), (328, 10), (981,), (328,))
lgbm으로 학습 및 검증평가
from lightgbm import LGBMClassifier,plot_importance
from sklearn.metrics import roc_auc_score
model = LGBMClassifier(random_state = SEED)
model.fit(x_train,y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid,pred)
=> 0.9081257023288255
특성 중요도 확인하기
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(15,10))
plot_importance(model,ax=ax)
plt.show()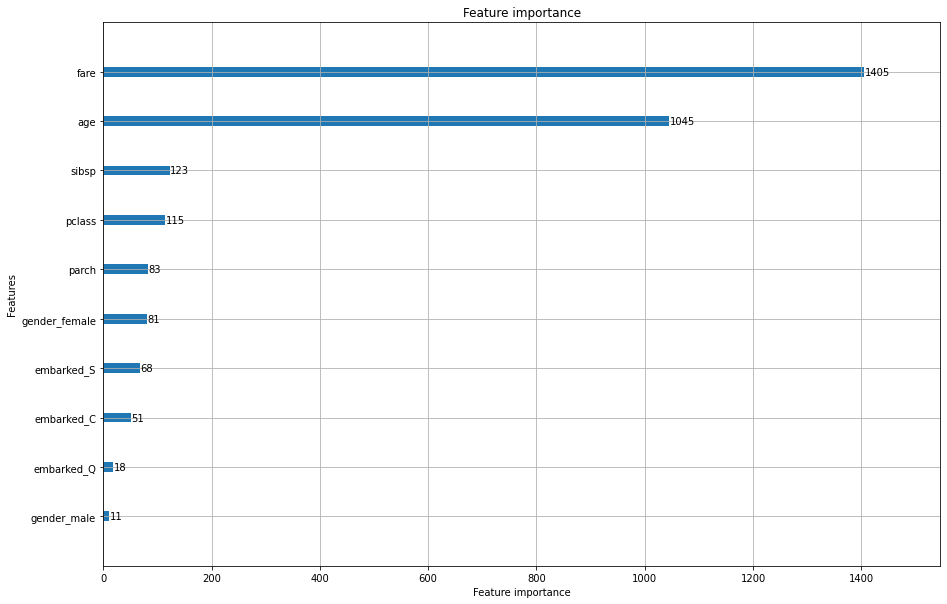
다음과 같이 중요도를 파악하면 새로운 피쳐를 넣는데 도움이 될 수 있다.
SHAP(Shapley Additive exPlanation)
- Shapley Value와 피쳐간 독립성을 핵심 아이디어로 사용하는 기법
- Shapely Value는 게임이론을 바탕으로 각 피쳐의 기여도를 계산하는 방법
- SHAP의 목적은 예측에 대한 각 피쳐의 기여도를 계산하여 관측치(X)의 예측값을 설명하는 것
- 기여도를 높이는데 관여했는지 낮추는데 관여했는지 알아보는 것
- 모든 가능한 조합에 대해서 하나의 특성의 기여도를 종합적으로 합한 값이다.
shap 설치
!pip install shap
학습된 모델을 넣어 생존에 대한 예측값을 나타낸다.
import shap
explainer = shap.TreeExplainer(model) # 학습된 모델을 넣는다.
shap_values = explainer.shap_values(x_valid) # x_valid.shape만큼 나온다.
shap_values[1] # 1에 대한 예측분류
=>
array([[-3.43519370e-01, -2.76856108e-01, 1.46509192e-01, ...,
-1.60094090e-01, -5.37443819e-03, -1.29870449e-01],
[ 1.01818364e+00, 1.36226915e-03, 2.81918238e-01, ...,
-1.37965890e-03, 2.31098011e-03, -3.47292038e-03],
[-3.00808044e-01, 3.07045060e-02, 1.23233794e-01, ...,
-9.20413841e-02, 5.64413349e-03, -2.26436110e-01],
...,
[ 8.65193228e-01, -6.85584808e-01, -1.94237138e-03, ...,
-1.26358351e-01, 2.16673502e-04, -3.96051764e-02],
[-2.58714498e-01, 8.43622024e-01, 2.16339266e-01, ...,
-1.19574213e-01, 1.79965719e-03, -1.14295550e-01],
[-1.00449910e+00, 3.34385041e-01, 2.07858402e-01, ...,
3.76476839e-01, -2.74989416e-03, 2.79466546e-01]])
force_plot
- 하나의 샘플에 대한 해석을 하고 싶을 때 사용
shap.initjs() # 자바스크립트 초기화
shap.force_plot(explainer.expected_value[1],shap_values[1][-1,:],x_valid.iloc[-1,:]) # 하나의 샘플만 넣기위해 shap_values[1] 마지막값이 -1이 잘 나와 넣었다.
코랩에서는 셀마다 자바스크립트를 초기화 해주어야 한다.

파란색 1로 예측하기 위한 확률을 낮추는 것, 빨간색은 반대이다.
넓이는 얼마나 기여했는가를 나타낸다.
위와 같이 fare가 적고 pclass가 3등급이면 죽을 확률이 높다 그래서 1로 예측하기 위한 확률이 낮다.
한사람마다 정보를 확인할 수 있고, 여러 개를 넣으면 해석하기 어렵다.
shap.summary_plot
shap.summary_plot(shap_values[1],x_valid)
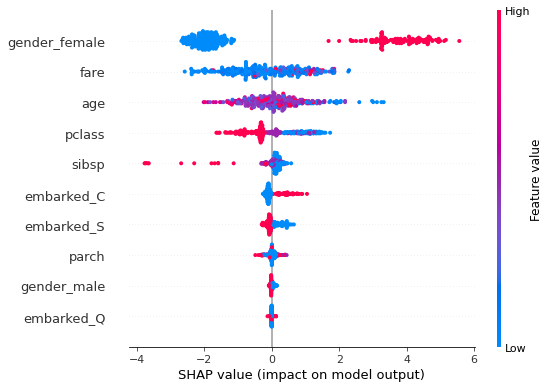
동시에 보지말고 각각 보는 것이 해석에 용이하다.
새로운 피쳐의 인사이트를 얻기 위해 사용할 수도 있다.
shap.dependence_plot
- 산점도를 그릴 수 있다.
shap.dependence_plot("age",shap_values[1],x_valid,interaction_index=None)

음의 상관관계로 나이가 낮아질수록 생존률이 올라간다는 것을 알 수 있다.
EDA를 따로 모델이 대체해줘서 편리하다.
shap.dependence_plot("pclass",shap_values[1],x_valid)
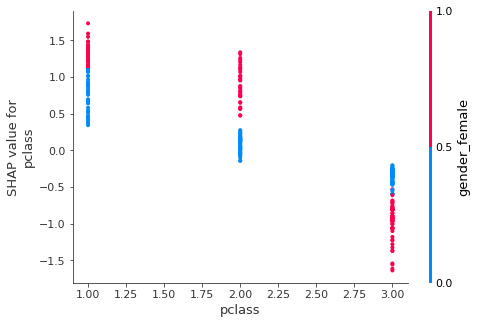
plcass와 연관성이높은 피처를 찾아 그려준다.
pclas는 여자인지 아닌지 여부가 중요하다는 것을 알 수 있다.
for문 이용
for col in x_valid.columns:
shap.dependence_plot(col,shap_values[1],x_valid)
print() # 간격을 줌!
각 컬럼별로 shap.dependence_plot을 나타냈다.
해석
pclass 클래스 1,2인 경우는 여자인 경우가 생존률이 높고,
pclass가 3이면 남자가 생존률이 높다.
-> 빈곤층 생존률이 낮지만 그 중에서 그나마 남자의 생존률이 높다.
age가 적고 여자일 경우 생존률이 낮아진다.
그리고 나이가 높아지면 성별은 생존률과 상관없이 많이 떨어진다.
-> 15세 이하의 경우 남아의 생존률이 높았다.
그 이유로는 남자아이가 사회적으로 더 쓸모있기 때문일 것이다. (남아선호사상)
15세 이후로는 여성의 생존률이 높아지다가 고령이 될수록 성별은 생존률과 상관이 없어진다.
sibsp이 0인 경우는 여성의 생존률이 높고, 1, 2인 경우는 남성의 생존률이 높다.
그리고 sibsp이 2이상일 때는 여성이 덜 죽었다.
-> 2명 이상은 챙겨야할 사람이 많아 생존률이 떨어진다.
parch가 0이고, fare가 높으면 생존률이 높다.
parch가 1이상인 경우는 오히려 요금이 높을수록 생존률이 적어졌다.
-> 요금과 상관없이 챙겨야할 사람이 많아서 그런 것 같다.
fare가 높고, sibsp이 높을수록 생존률이 높다
-> 계급사회에서 돈이 많은 사람은 당연히 고위 계급일 경우가 높고,
형제자매가 많으면 도움받을 기회도 많아 생존률이 높다.
c항구를 제외한 나머지 항구는 pclass 상관없이 생존률이 떨어졌고,
c항구는 클래스가 높을수록 생존률이 높았다.
-> c항구 자체에 생존률이 높은 것으로 보아 c항구는 잘사는 동네이다.
q항구는 sibsp가 높을수록 생존률이 높아진다.
-> q항구는 다른 항구와 다르게 sibsp가 나온 것으로 보아 q항구는 형제자매가 있는 사람이 많을 것이다.
s항구를 제외한 나머지 항구에서는 pclass가 낮을수록 생존률이 높다.
그리고 s항구는 생존률 pclass에 상관없이 생존률이 떨어졌지만 plcass가 높을수록 생존률이 그나마 높아졌다.
-> s항구를 제외한 나머지 항구에는 여성의 비율이 s항구에 비해 많을 것이다.
q 항구의 여성 비율: 0.4878048780487805
c 항구의 여성 비율: 0.4185185185185185
s 항구의 여성 비율 : 0.31986899563318777
-> 가설이 맞다!
강사님이 내 해석에서 남아선호사상을 보고 웃으셨다. 단어 선택이 웃기긴 했다.
남아선호사상을 대체할 단어가 없어서 찾아보는데 남아선호사상은 동서양을 모두 포함하여 나타내는 말이라 나와있었다.
데이터 분석이 너무 재밌는 것 같다!
'AI 공부 > 머신러닝' 카테고리의 다른 글
| (머신러닝) data leakage (0) | 2022.09.15 |
|---|---|
| (머신러닝) 비지도 학습 - 차원축소 (1) | 2022.09.14 |
| (머신러닝) 모델튜닝 (1) | 2022.09.13 |
| (머신러닝) 앙상블 (0) | 2022.09.13 |
| (머신러닝) 머신러닝 모델 (2) | 2022.09.13 |


댓글