728x90
선형회귀(Linear regression)
- 원인이 되는 설명 변수(독립변수, Feature)에 따른 종속변수(class,label,target)의 결과를 예측

- 사이킷 런에서 제공해주는 당뇨병 진행도 데이터셋 받아오기
from sklearn.datasets import load_diabetes
diabets = load_diabetes()
data = diabets.data
target = diabets.target
from sklearn.model_selection import train_test_split
SEED =42
x_train, x_valid, y_train, y_valid = train_test_split(data,target,random_state=SEED)
x_train.shape, x_valid.shape, y_train.shape, y_valid.shape
=> ((331, 10), (111, 10), (331,), (111,))
선형회귀 적용
from sklearn.linear_model import LinearRegression
import numpy as np
model = LinearRegression()
model.fit(x_train,y_train)
pred = model.predict(x_valid)
MAE와 RMSE
from sklearn.metrics import mean_absolute_error # MAE
mse = mean_absolute_error(y_valid,pred)
mse
=> 41.548363283252066
from sklearn.metrics import mean_squared_error # RSME
mse = mean_squared_error(y_valid,pred) ** 0.5
mse
=> 53.36942296795932
로지스틱 회귀분석 (Logistic Regression)
- Regression(회귀)라는 단어가 들어가지만 분류 모델이다.
- 선형회귀 + 시그모이드 함수
- 예측 결정으로 시그모이드 함수 사용
- 시그모이드 함수 특징
- 입력값이 양수 무한대로 입력이 들어가도 1에 가깝게 출력
- 입력값이 음수 무한대로 입력이 들어가도 0에 가깝게 출력

- 사이킷런에서 제공해주는 0~9까지 손글씨 데이터셋을 받아오기
from sklearn.datasets import load_digits
digits = load_digits()
data = digits.data / 255 # minmax 스케일 255로 나눈다 (0~255이기 때문에 나누기만하면 된다!)
target = (digits.target == 9).astype(int)
Hold out
from sklearn.model_selection import train_test_split
x_train,x_valid,y_train,y_valid= train_test_split(data,target,random_state=SEED)
x_train.shape, x_valid.shape, y_train.shape, y_valid.shape
=> ((1347, 64), (450, 64), (1347,), (450,))
결과
from sklearn.metrics import roc_auc_score
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(random_state=SEED)
model.fit(x_train,y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid,pred)
=> 0.9587997512437811
K-NN
- 최근접 이웃 알고리즘
- 새로운 샘플이 K개 가까운 이웃을 이용해서 예측
- 제일 가까운 데이터 포인트를 찾아서 결정하는 방식
- 회귀, 분류 둘 다 사용한 알고리즘
- K는 홀수개를 줘야한다. (짝수 개일 경우 거리에 따라 가중치 부여)

- 데이터 포인트간의 거리를 측정하는 방법
- 유클리드 거리와 맨하튼 거리가 있다.

KNeighborsClassifier
- n_neighbors : 이웃수
- weights :
- uniform : 기본값으로 거리에 상관없이 모든 이웃에 대해 동일 취급
- distance : 거리에 따라 가중치를 부여
- p
- 2: 기본값으로 유클리드 거리
- 1: 맨하튼 거리
적용
from sklearn.neighbors import KNeighborsClassifier # 하이퍼 파라미터 지정
model = KNeighborsClassifier(n_neighbors=10,p=1,weights="distance")
model.fit(x_train,y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid,pred)
=> 0.9982898009950248
인공신경망(Neural Network)
- 퍼셉트론(perceptron)
- 초기 형태의 인공신경망으로 다수의 입력으로부터 하나의 결과를 내보내는 알고리즘
- MLP(Multi-layer Perceptron)
- 퍼셉트론으로 이루어진 층(layer)을 여러개 순차적으로 붙여놓은 상태
- 회귀, 분류 모두 사용가능한 알고리즘
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(random_state=SEED,hidden_layer_sizes=(100,50),max_iter=500) # 100의 뉴런과 50개의 뉴런 넣음!
model.fit(x_train,y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid,pred)
=> 0.9984970978441128
의사결정나무(Decision Tree)
- 회귀, 분류 둘다 사용가능한 알고리즘
- 여러가지 규칙을 순차적으로 적용하면서 트리기반의 규칙을 만들어 예측하는 알고리즘 (순수도가 높아지는 방향으로 분할)
- 데이터를 분할하는데 순수도가 높은 방향으로 규칙을 정한다.
- 순수도
- 각 노드의 규칙에 의해 동일한 클래스가 포함되는 정도를 의미
- 부모노드의 순수도에 비해 자식노드들에 순수도가 증하가도록 트리를 형성
- 순수도의 척도
- gini와 entropy : 둘다 0에 가까울수록 순수도가 높아진다.
- root node: 최상단에 위치 (제일 중요하다.)
- internal node: 중간에 위치한 노드
- link:true,False
- leaf node: 최종 분류값을 가진다 (결정)
- 과적합이 심하다..!!
위 그림은 의사결정나무가 특성(Feature)에 대한 규칙을 정하는 방법이다.
가중치가 필요없기 때문에 스케일링이 필요가 없다.
Decision
from sklearn.tree import DecisionTreeClassifier
hp = {
"random_state":SEED,
"max_depth":5, # 과적합 방지용
"min_samples_split":2, # 노드를 분할하는데 필요한 최소 샘플 수
"criterion" : "entropy", # 순수도 척도
"min_samples_split" : 10, # 최대리프노드 수 (과적합 방지용)
'max_leaf_nodes' : 20, # 리프노드에 있어야 할 최소 샘플 수
}
model = DecisionTreeClassifier(**hp) # 키워드 아규먼트
model.fit(x_train,y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid,pred)
=> 0.9328358208955224
의사결정나무 시각화하기
타이타닉데이터 가져오기
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
df = sns.load_dataset("titanic")
df.head()
데이터프레임 만들기
cols = ["pclass","age","sibsp","parch","fare"]
features = df[cols]
target = df["survived"]
from sklearn.preprocessing import OneHotEncoder
cols = ["sex","embarked"]
enc = OneHotEncoder(handle_unknown="ignore")
tmp = pd.DataFrame(
enc.fit_transform(df[cols]).toarray(),
columns = enc.get_feature_names_out()
)
features = pd.concat([features,tmp],axis=1)
features.head()
=>
pclass age sibsp parch fare sex_female sex_male embarked_C embarked_Q embarked_S embarked_nan
0 3 22.0 1 0 7.2500 0.0 1.0 0.0 0.0 1.0 0.0
1 1 38.0 1 0 71.2833 1.0 0.0 1.0 0.0 0.0 0.0
2 3 26.0 0 0 7.9250 1.0 0.0 0.0 0.0 1.0 0.0
3 1 35.0 1 0 53.1000 1.0 0.0 0.0 0.0 1.0 0.0
4 3 35.0 0 0 8.0500 0.0 1.0 0.0 0.0 1.0 0.0
결측치 처리
features.isnull().sum()
=>
pclass 0
age 177
sibsp 0
parch 0
fare 0
sex_female 0
sex_male 0
embarked_C 0
embarked_Q 0
embarked_S 0
embarked_nan 0
dtype: int64
중앙값으로 채우기
features.age = features.age.fillna(features.age.median())
의사결정트리 만들기
hp = {
"random_state":SEED,
"max_depth":3, # 과적합 방지용
"min_samples_split":2
}
model = DecisionTreeClassifier(**hp)
model.fit(features,target)
중요도 파악
model.feature_importances_
=>
array([0.21352543, 0.0618669 , 0.04492651, 0. , 0.05080152,
0. , 0.62887964, 0. , 0. , 0. ,
0. ])
피처 컬럼확인
features.columns
=>
Index(['pclass', 'age', 'sibsp', 'parch', 'fare', 'sex_female', 'sex_male',
'embarked_C', 'embarked_Q', 'embarked_S', 'embarked_nan'],
dtype='object')
시각화
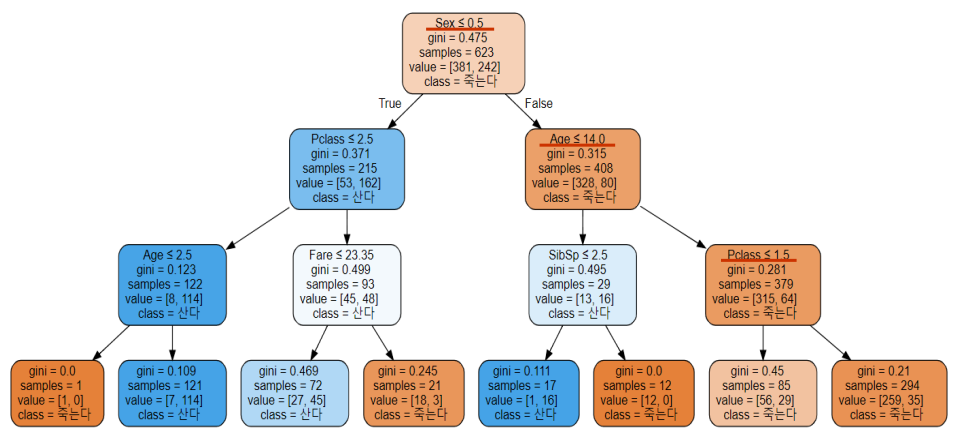
from sklearn.tree import export_graphviz
export_graphviz(model,out_file="tree.dot",feature_names=features.columns,class_names=["죽는다","산다"])
파일 형태로 저정하여 필요할 때 불러와 시각화가 가능하다.
import graphviz
with open("tree.dot") as f:
tree = graphviz.Source(f.read()) # 그래프 객체가 반환된다.
tree
오늘은 머신러닝에 대한 여러 모델에 대해 알아보았다.
각 모델의 장단점을 파악해 필요한 데이터에 적용시키는 법을 익히는 것이 중요한 것 같다.
728x90
'AI 공부 > 머신러닝' 카테고리의 다른 글
| (머신러닝) 모델튜닝 (1) | 2022.09.13 |
|---|---|
| (머신러닝) 앙상블 (0) | 2022.09.13 |
| (머신러닝) sklearn (0) | 2022.09.11 |
| (머신러닝) 교차검증과 과적합 (0) | 2022.09.07 |
| (머신러닝) 결측치 및 스케일링 (0) | 2022.09.07 |


댓글