728x90
머신러닝 검증방식
데이터 불러오기 (숫자)
import numpy as np
from sklearn.datasets import load_digits
digits = load_digits()
data = digits.data
target = digits.target
data.shape, target.shape
Holdout
- 빠른 속도로 검증가능
- 이전에 test_split 한 것이 holdout 방식!

K-Fold 교차검증(K-Fold cross validation)
- 전체데이터를 k등분하고, 각 등분을 한번씩 검증데이터로 사용
- 각 폴드의 성능 결과값을 평균내서 검증

Holdout 방식을 사용하는 것보다 교차검증을 사용하면 여러 valid 있어 성능의 검증을 더 신뢰할 수 있다.
교차검증 예시
from sklearn.model_selection import KFold
cv = KFold(n_splits = 5) # (n_splits: k값)늘릴수록 성능이 조금씩 늘어난다.
gen = cv.split(data)
gen # 제너레이터를 통해 검증데이터에 대한 인덱스와 학습데이터에 대한 인덱스를 동시에 뽑아준다.
next(gen)
=>
(array([ 360, 361, 362, ..., 1794, 1795, 1796]),
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
...
데이터가 어떠한 규칙에 정렬되어있을 수도 있기 때문에 셔플을 한다. (SEED = 42로 고정!)
from typing_extensions import dataclass_transform
cv = KFold(n_splits=5, shuffle=True,random_state=SEED)
gen = cv.split(data)
next(gen)
=>
(array([ 0, 1, 2, ..., 1794, 1795, 1796]),
array([ 23, 29, 30, 32, 44, 49, 51, 59, 65, 67, 69,
70, 71, 73, 76, 78, 99, 109, 111, 115, 123, 124,
135, 141, 162, 168, 170, 173, 184, 185, 188, 196, 203,
210, 212, 220, 233, 237, 239, 240, 244, 247, 250, 251,
254, 259, 261, 270, 271, 275, 289, 297, 298, 300, 303,
305, 307, 316, 322, 324, 331, 332, 339, 342, 344, 350,
...
for 문으로 데이터 파악
for tri,vai in cv.split(data):
print(tri.shape)
print(vai.shape)
=>
(1437,)
(360,)
(1437,)
(360,)
(1438,)
(359,)
(1438,)
(359,)
(1438,)
(359,)
KFold 검증해보기
from sklearn.tree import DecisionTreeClassifier
score_list = []
for tri,vai in cv.split(data):
# 학습데이터
x_train = data[tri]
y_train = target[tri]
# 검증데이터
x_valid = data[vai]
y_valid = target[vai]
model = DecisionTreeClassifier(max_depth=10,random_state=SEED)
model.fit(x_train,y_train)
score = model.score(x_valid,y_valid) # 정확도가 반환된다.
score_list.append(score)
np.mean(score_list)
=> 0.8508511296812132
각 폴드의 성능 결과값을 평균내어 0.85085가 나왔다.
층화추출(Stratified K-Fold cross validation)
- 불균형한 클래스 데이터 집합을 위한 KFold 방식
- 정답데이터에서 특정 클래스가 특이하게 많거나 매우 적을 때 사용
- 정답데이터의 클래스 비율에 맞춰 학습과 검증데이터를 분배한다.
- 검증에서 높게 나와도 실제데이터에서 잘 맞춘다는 보장이 없다. (y값을 잘 주어야한다.)

from sklearn.model_selection import StratifiedKFold
cv = StratifiedKFold(n_splits = 5, shuffle=True, random_state=SEED)
score_list = []
for tri, vai in cv.split(data,target): # 정답값도 같이 줘야한다. 클래스비율을 알려줘야하기 때문에 (ex. 여성,남성의 비율)
# 학습데이터
x_train = data[tri]
y_train = target[tri]
# 검증데이터
x_valid = data[vai]
y_valid = target[vai]
model = DecisionTreeClassifier(max_depth=10,random_state=SEED)
model.fit(x_train,y_train)
score = model.score(x_valid,y_valid) # 정확도가 반환된다.
score_list.append(score)
np.mean(score_list)
=> 0.8553048591767254
층화추출은 KFold와 다르게 y정답값을 같이 주어야한다.
그래야 클래스 비율을 알고 층을 나눌 수 있기 때문이다.
sklearn.model_selection 모듈을 이용한 교차검증 방법
- 잘안쓰게 된다.
from sklearn.model_selection import cross_val_score # for문을 안써도 된다.
model = DecisionTreeClassifier(max_depth=10,random_state=SEED)
cv = KFold(n_splits=5,shuffle=True,random_state=SEED)
score_list = cross_val_score(model,data,target,cv=cv,scoring='accuracy',n_jobs=-1) # 5개 폴더로 cv, n_job = cpu를 전부다 쓰겠다.(속도개선)
score_list
=> array([0.85 , 0.87222222, 0.83008357, 0.84958217, 0.85236769])
np.mean(score_list)
=> 0.8508511296812132
위 방법은 잘 안쓰게 된다고 하셨다. 그렇다고 아예 안쓰는 것은 아니니 이해하고 넘어가자!
과적합
- 과대적합(overfitting)
- 모델이 학습데이터에 필요 이상으로 적합
- 데이터 내의 존재하는 규칙뿐만 아니라 불완전한 샘플도 학습
- 과대적합만 방지해도 좋은 모델을 만들 수 있다.
- 과소적합(underfitting)
- 모델이 학습데이터에 제대로 적합하지 못함
- 데이터 내에 존재하는 규칙도 제대로 학습 못함 (ex. 로또)
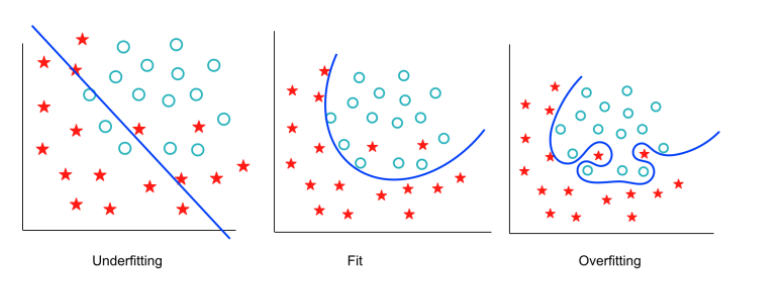
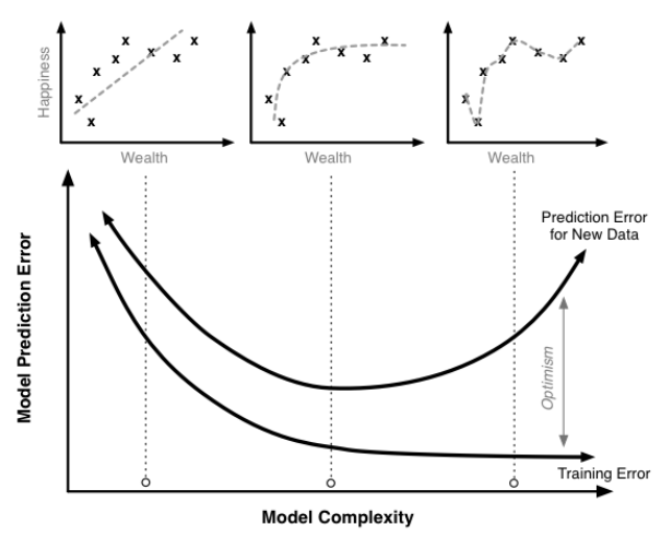
예시
데이터 불러오기
import seaborn as sns
df = sns.load_dataset('titanic')
cols = ["age","sibsp","parch","fare"]
features = df[cols]
target = df["survived"]
원핫인코딩하기
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
cols = ["pclass","sex","embarked"]
enc = OneHotEncoder()
tmp = pd.DataFrame(
enc.fit_transform(df[cols]).toarray(),
columns = enc.get_feature_names_out()
)
tmp
features = pd.concat([features,tmp],axis = 1)
features.head()
결측치 채우기
features.age = features.age.fillna(-1)
features.isnull().sum().sum()
=> 0
분류
from sklearn.model_selection import train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(features,target,random_state=SEED,test_size=0.2)
x_train.shape, x_valid.shape, y_train.shape, y_valid.shape
=> ((712, 13), (179, 13), (712,), (179,))
- 모델 복잡도에 따른 overfitting 예제
model = DecisionTreeClassifier(max_depth=20,random_state=SEED) # 크기를 비교하기 때문에 스케일링을 조절해도 의미가 없다.
model.fit(x_train,y_train)
model.score(x_train,y_train), model.score(x_valid,y_valid) # 학습데이터는 잘 맞추지만 검증 데이터는 떨어진다.
=> (0.9803370786516854, 0.770949720670391)
- 모델의 복잡도를 줄인 예제
model = DecisionTreeClassifier(max_depth=3,random_state=SEED) # 크기를 비교하기 때문에 스케일링을 조절해도 의미가 없다.
model.fit(x_train,y_train)
model.score(x_train,y_train), model.score(x_valid,y_valid) # 학습데이터와 검증 데이터가 차이가 없고, 성능이 올라갔다.
=> (0.8146067415730337, 0.7932960893854749)
728x90
'AI 공부 > 머신러닝' 카테고리의 다른 글
| (머신러닝) 머신러닝 모델 (2) | 2022.09.13 |
|---|---|
| (머신러닝) sklearn (0) | 2022.09.11 |
| (머신러닝) 결측치 및 스케일링 (0) | 2022.09.07 |
| (머신러닝) 성능측정 (0) | 2022.09.06 |
| 인공지능과 머신러닝의 개념 (2) | 2022.09.05 |


댓글