728x90
딥러닝(Deep Learning)
- 딥러닝은 머신러닝 알고리즘 중 하나인 인공신경망을 다양하게 쌓은 것
- 인공신경망을 여러 겹으로 쌓으면 딥러닝

딥러닝은 머신러닝이 처리하기 어려운 데이터(비정형 데이터)를 더 잘 처리
- 3차원 이상 데이터를 잘 처리한다.

딥러닝은 만능?
- 학습을 위해 상당히 많은 양의 데이터를 필요로 함 (전이학습을 통해 어느정도 해결 = 자연어쪽이 발달됨!)
- 계산이 복잡하고 수행시간이 오래 걸림
- 이론적 기반이 없어 결과에 대한 장담이 어려움 (노드 층을 어떻게 쌓을지에 대한 가이드라인만 있다. 정답이 없다는 뜻 = 다양한 실험 필요하다.)
- 블랙 박스 접근 방식
딥러닝은 이미지와 자연어로 2가지로 나뉠 수 있는데 둘다 잘하기는 쉽지 않다.
한 분야를 선택해서 가는 것이 좋다.
손실함수(Loss Function)
- 모델의 출력값(Output)과 정답과의 차이(오차,Error)를 의미
- 신경망이 학습할 수 있도록 해주는 지표
- 손실 값이 최소화 되도록 하는 가중치(weight)와 편향(bias)를 찾는 것이 학습의 목표
회귀(Regression)에서의 손실함수
- MSE (Mean Squared Error)
- L2 loss
- 이상치에 민감
- MAE (Mean Absolute Error)
- L1 loss
- 이상치에 강건
- 시간이 남고, 성능을 쥐어짤 때 사용 (시계열 예측할 때 좀 더 좋다.)

다중 분류(Multi-class Classification)에서의 손실함수
- CE(Cross Entropy)
- 예측확률이 실제값과 얼마나 비슷한가를 측정
- 하나의 샘플에 대해 손실을 구하면 전체 샘플에 대한 손실이 나온다. (원핫인코딩)
다중 분류를 할 때 CE를 사용한다고 암기하기!

이진 분류(Binary Classification)에서의 손실함수
- BCE(Binary Cross Entropy)
이진분류는 BCE를 사용한다고 암기하기!
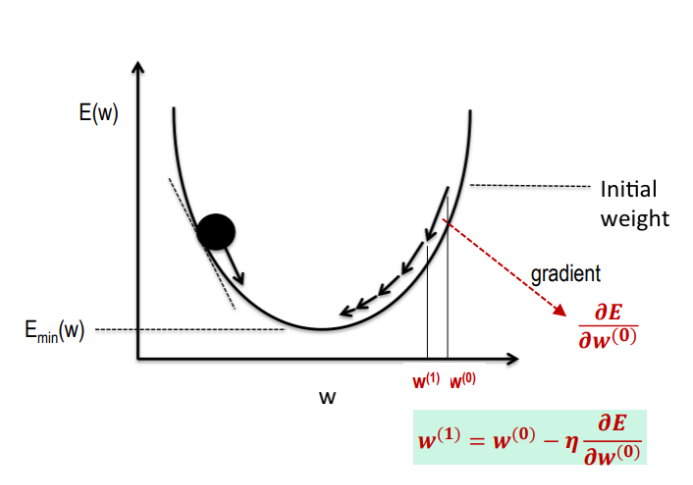
경사하강법(Gradient Descent)
- 모델이 잘 학습할수 있도록 기울기(변화율)을 사용하여 모델의 파라미터를 조정하는 방법
- 예측값과 실제값을 비교하여 손실을 구한다.
- 손실이 작아지는 방향으로 파라미터를 수정한다.
- 이과정을 반복한다.
- 경사(기울기): 파라미터에 대한 오차의 변화
- 기울기 + : 파라미터 ↓
- 기울기 - : 파라미터 ↑
- 학습률을 곱해서 가중치를 업데이트한다.(대게로 0.001이다.)
기울기가 증가하면 파라미터를 낮추고, 기울기가 감소하면 파라미터를 증가시킨다.
경사하강법을 사용할 시 손실함수 값의 변화에 따라 학습률을 곱해 가중치를 업데이트를 해야한다.
학습률(Learning Rate)
- 파라미터를 업데이트하는 정도를 조절하기 위한 값
학습률이 너무 큰 경우
- 글로벌 최소값을 못찾음
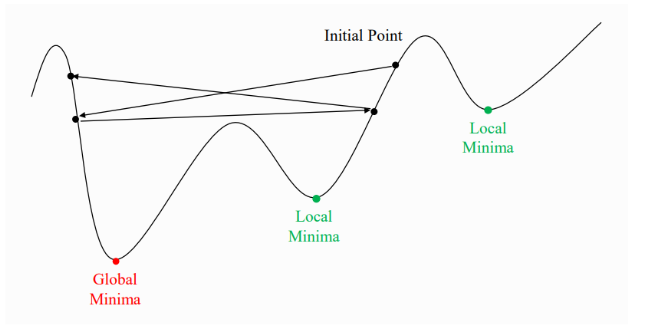
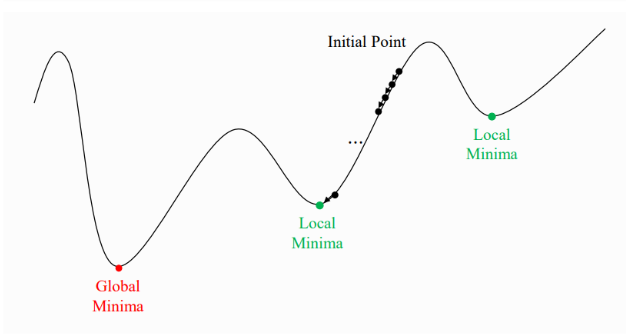
학습률이 너무 작을 경우
- 지역 최소점에서 못 빠져 나온다.
- 정규화를 이용하면 경사를 완만하게 만들어 극솟값에 빠지는 가능성을 낮춰준다.
역전파(Back-propagation)
- 뒤로 가는 과정
- 컴퓨터가 예측값의 정확도를 높이기 위해 출력값과 실제 예측하고자 하는 값을 비교하여 가중치를 변경하는 작업을 말합니다.
- backward pass
- 효율적인 계산을 위해 역전파 알고리즘을 사용
- 손실값을 구해 이 손실에 관여하는 가중치들을 손실이 작아지는 방향으로 수정하는 알고리즘
- 파라미터를 업데이트할때 필요한 손실에 대한 기울기를 역방향으로 업데이트
- 손실을 구하고 역전파를 해줘야한다.
- 기여한만큼 가중치가 달라지고 업데이트가 된다.
- 역전파 코드는 실행을 해주어야한다.
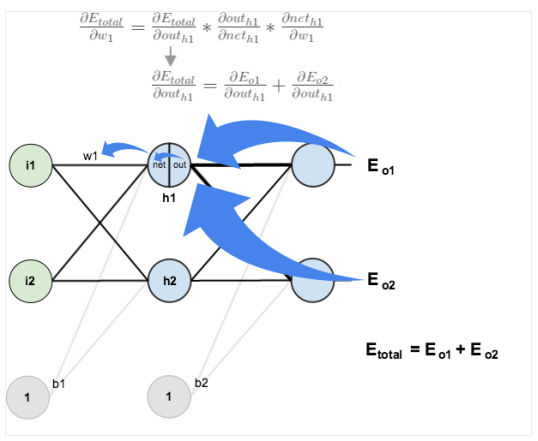
경사 소실 문제와 활성화 함수
- 층이 깊어지면서 역전파과정에서 가중치를 수정하려는 기울기가 중간에 0이 되어버리거나 0에 매우 가깝게 작아지는 경사 소실(vanishing gradient) 문제가 발생
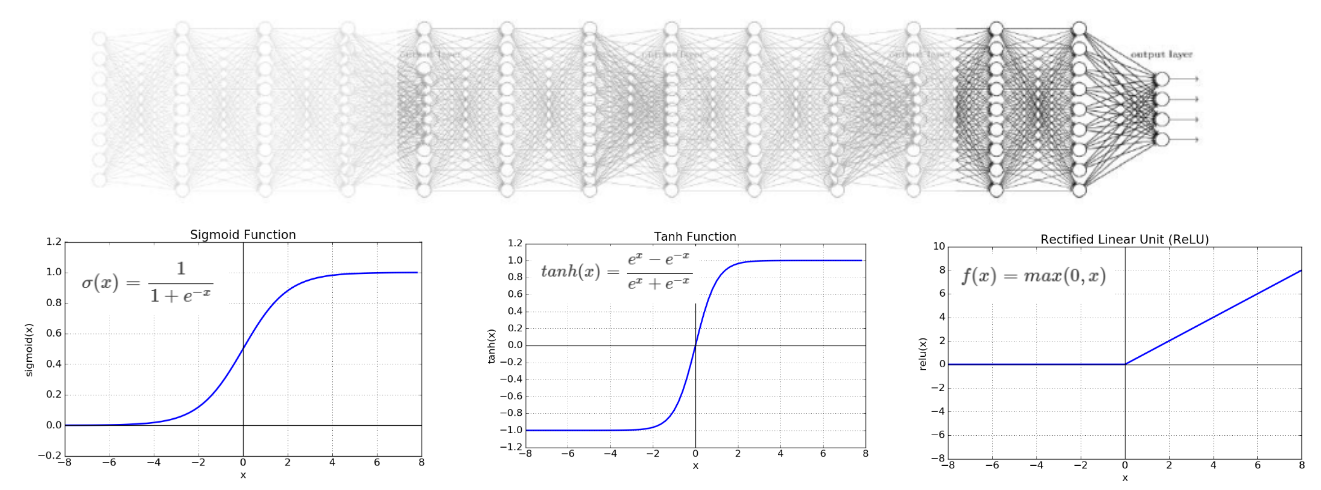
- ReLU 양수일 경우 그대로 음수일 경우 0으로 출력 (음수가 0이라 노드가 죽어버린다.)
- 변종 ReLU으로 LeakyReLU, ELU가 있다.
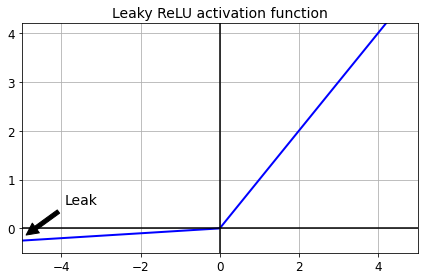
하이퍼 파라미터 $α$는 이 함수가 새는 정도를 결정합니다.
즉 샌다는 것은 음수 영역에서의 함수의 기울기를 의미하며 보통 0.01로 설정합니다.
바로 이 작은 기울기가 LeakyRelu가 절대 죽지 않게 해주는 것입니다.
실제로 성능도 훨씬 좋습니다. 다음은 LeakyRelu 사용법입니다. 적용하려는 층 뒤에 붙여주면 됩니다.
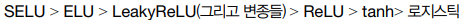
- 네트워크가 자기 정규화 되지 못한다면 SELU보단 ELU
- 실행 속도가 중요하다면 LeakyReLU
- 신경망이 Overfitting되었다면 RReLU
- 그러나 대부분의 라이브러리와 하드웨어 가속기들은 ReLU에 특화되어있으므로, 속도를 위한다면 Relu
배치(Batch)
- 일을 모아서 한번에 처리하는 단위
- 배치 경사하강법
- 모든 학습데이터를 사용하여 gradient 계산 및 update
- 미니배치 경사하강법
- 학습데이터를 미니 배치로 쪼개어 미니배치 단위로 gradient 계산 및 update (메모리에 다 못올리기 때문에)
- 미니배치방식으로 모든 학습데이터를 학습 완료하면 한번의 에폭(epoch)이 완료
- 지역최소점에서 빠져나오기 힘듦
- 적절한 학습률을 선택하기 어려움
- 경험에 의해서 적절한 하이퍼 파라미터 지정

Optimizer
- 미니배치 경사하강법의 방식을 보완하고, 학습 속도를 높이기위한 알고리즘
- Momentum
- 기존 업데이트에 사용했던 경사의 일정 비율을 남겨서 현재의 경사와 더하여 업데이트함
- Adagrad
- 각 파라미터의 update 정도의 따라 학습률의 크기를 다르게 해줌
- RMSProp
- Adagradd의 경우 update가 지속됨에 따라 학습률이 점점 0에 가까워지는 문제가 발생
- 이전 update 맥락을 보면서 학습률 조정하여 최신 기울기를 더 크게 반영
- Adam (가장 많이 사용)
- Momentum 과 RMSProp 장점을 함께 사용
- 가장 많이 사용하는 Optimizer
정리하기
- 미니배치학습을 위한 데이터셋을 구성 (클래스로 구성)
- 딥러닝 모델인 인공신경망을 구현
- 우리가 풀고자하는 문제에 맞는 손실함수 사용
- 경사하강법에 문제를 보완하기 위해 적절한 옵티마이저를 선택 (Adam 사용)
- 학습 과정
- 데이터셋을 딥러닝 모델에 넣는다.
- 예측 결과에 대한 손실을 구한다.
- 역전파를 통해 모델 가중치의 기울기를 구한다.
- 옵티마이저를 이용하여 모델 가중치를 업데이트한다.
728x90
'AI 공부 > 딥러닝' 카테고리의 다른 글
| TabNet 정리 (0) | 2022.12.12 |
|---|---|
| 평가 지표 (0) | 2022.11.07 |
| 딥러닝 (RNN,LSTM,GRU) (1) | 2022.10.03 |
| 딥러닝 (손실함수) (0) | 2022.10.02 |
| 딥러닝 (pytorch) (0) | 2022.10.02 |


댓글